SYCL™ Graphs
22 January 2024
When working with accelerated applications, such as when using GPUs, developers write compute kernels that are executed one by one on the accelerator. This is called “offloading”, as in, developers are moving computation off the CPU onto the GPU. Typically, computational kernels operate on data that is coming from the host, perform some manipulation with that data, and then data goes back to the host CPU so that the application can continue. However, as more workloads are offloaded to accelerators, it has become increasingly common to offload multiple kernels that operate with data to the device. The process of offloading, by its nature of synchronizing two different processors for even a brief period of time, introduces overhead, typically seen in terms of latency (i.e. time before submission of a kernel and actual execution) and additional CPU “busywork” (CPU threads need to stop and synchronize multiple times to handshake and pass data around).
However, in some applications developers can identify a group of compute kernels that could be scheduled together on the same submission, because they operate with a set of data on the accelerator. And, even more interestingly, in some cases the main loop of the application actually re-issues the same group of compute kernels multiple times, but changing the inputs and outputs only.
It is for these situations that we have designed a SYCL extension called “SYCL Graph” that allows you to define a computational graph of dependencies between compute kernels and memory operations, batch it together and submit it as many times as you want! Being SYCL multi-platform, this feature maps to similar abstractions on the different backends and hardware that is supported, for example it will map to CUDA Graphs on NVIDIA GPUs, Command Buffers in OpenCL, or utilize Command Lists in Level Zero and Vulkan, among others.
In this blog post, we elaborate on this execution model and the API users can interface with to try it out for themselves, we provide instructions on how to use it in the DPC++ implementation, and finally include some next ideas and plans in the roadmap.
The Extension
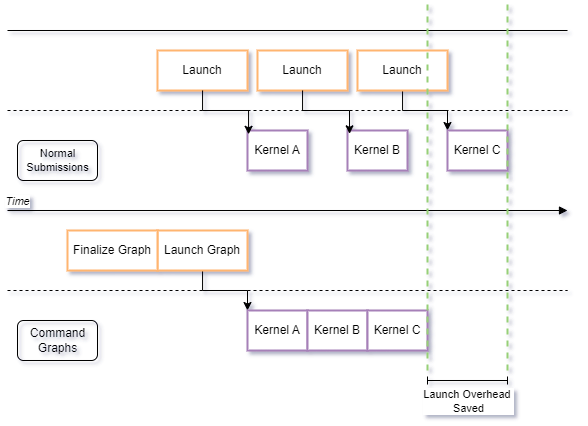
In SYCL applications commands are submitted to a queue for execution, optionally with dependencies. These submissions define an implicit dependency graph of SYCL command groups at runtime in the form of a directed acyclic graph (DAG). However because command execution is tied to command submission, commands are executed eagerly and the full DAG of commands submitted to the runtime is not known until they have all been submitted for execution. In collaboration with Intel, Codeplay have developed a command-graph extension for SYCL to remove this restriction - sycl_ext_oneapi_graph. This extension decouples command submission from command execution, allowing the user to define ahead of time the full DAG of commands that they wish to execute. The user can then submit this user-defined graph for execution repeatedly without the need for resubmission of individual commands.
Exposing this through the SYCL API opens up opportunities for optimization at both the SYCL runtime and graph levels such as: reduced host launch latency of commands through batching, the potential for whole graph optimizations, including kernel fusion, and an easier workflow for repeated execution of commands. For a full presentation about the extension and its implementation see the recorded IWOCL & SYCLCON 2023 talk - Towards Deferred Execution of a SYCL Command Graph.
Main objects
Command-Graph Class
The command_graph class represents a collection of commands which form a DAG of execution. A command-graph contains a number of Nodes (which represent the commands) and Edges (which define dependencies between Nodes). command_graph objects are initially created in the modifiable state. In this state both Nodes and Edges can be added to the graph, but it cannot be executed. A modifiable graph can be finalized to create a new graph in the executable state, which can no longer be modified by adding new nodes or edges, but can be submitted to a SYCL queue for execution. A command-graph targets a single device which is fixed on graph creation.
Nodes
As mentioned previously, an object of the node class represents a single command in the graph. More specifically they represent a SYCL command group. This can be a kernel execution, memory operation, or other SYCL command types.
Edges
An edge in the graph is not represented by a C++ object but represents a “happens-before” relationship between nodes. Edges may be either automatically inferred from the command groups submitted as nodes to the graph, or added manually, depending on the API being used.
APIs
The extension contains two different APIs which can be used to create command-graphs. They can be used separately or mixed together depending on your specific use case.
The “Record and Replay” API - This API records commands submitted to SYCL queues as nodes in the graph and automatically infers dependencies.
The “Explicit Graph Creation” API - This API lets the user explicitly define the nodes and edges of a graph, giving more control over its structure.
The next section will explore the use of both of these APIs with a practical SYCL example.
A Practical SYCL example
The following is an example of a basic SYCL program which will be used demonstrate how existing SYCL code can be modified to use command-graphs. This example uses USM memory and omits some minor details for simplicity.
using namespace sycl;
using namespace sycl_ext = sycl::ext::oneapi::experimental;
queue Queue{default_selector{}};
float *PtrA = sycl::malloc_device<float>(N, Queue);
float *PtrB = sycl::malloc_device<float>(N, Queue);
float *PtrC = sycl::malloc_device<float>(N, Queue);
// Init device data
auto InitEvent = Queue.submit([&](handler& CGH) {
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrA[id] = 1.0f;
PtrB[id] = 2.0f;
PtrC[id] = 3.0f;
});
});
auto EventA = Queue.submit([&](handler& CGH) {
CGH.depends_on(InitEvent);
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrA[id] += 1.0f;
});
});
auto EventB = Queue.submit([&](handler& CGH) {
CGH.depends_on(InitEvent);
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrB[id] += 1.5f;
});
});
auto EventC = Queue.submit([&](handler& CGH) {
CGH.depends_on({EventA, EventB});
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrC[id] += (PtrA[id] + PtrB[id]);
});
});
Queue.wait_and_throw();
// Do something with the data
“Graphifying” the code
We need to make some modifications to this code regardless of the API being used to enable command-graphs:
-
Create the modifiable graph before the commands you want to capture in the graph. Command-graphs require a context and the target device on construction, for example:
sycl_ext::command_graph Graph(Queue.get_context(), Queue.get_device()); -
After all the required commands have been added, we must finalize the graph. Finalizing performs the computationally expensive operations required to prepare the graph for execution on a device. In regular SYCL command submissions these will occur immediately before execution, affecting the total execution time from queue submission to a command finishing execution on a given device. By separating these operations the application can handle this cost up front, then execute the commands all at once, removing runtime overhead from repeated executions of the graph. Calling finalize() on the modifiable graph creates an executable graph object, for example:
auto ExecGraph = Graph.finalize(); -
Submit the executable graph to a queue for execution as many times as required. Note here we use the queue shortcut but you can also submit a command-graph inside a regular command group submission by using handler:: ext_oneapi_graph(
), for example: Queue.ext_oneapi_graph(ExecGraph);
Record & Replay API
The Record & Replay API allows easy capture of existing code which submits commands to a queue with minimal required changes. While the queue is in a capture state commands submitted to it will be added as nodes to the graph rather than being submitted for execution on a device. To enable queue capture using this API we simply need to add calls to graph:: begin_recording(queue) and graph::end_recording(queue) surrounding the queue submissions, for example:
Graph.begin_recording(Queue);
// Submit commands to the queue here via Queue.submit()...
Graph.end_recording(Queue);
// Finalize and submit graph.
Note that events returned from submissions to a queue which is currently recording commands to a graph cannot be used in any way other than to define dependencies for command-graph commands. You also cannot define dependencies for graph commands on events which come from outside the command-graph on which they were recorded.
Commands recorded in this way have their dependencies (edges) inferred from the normal SYCL mechanisms: user of buffer accessors and calls to handler::depends_on(). This is used by the runtime to build the full DAG in the same way that a normal SYCL program would.
The final modified example code after these changes looks as follows:
using namespace sycl;
using namespace sycl_ext = sycl::ext::oneapi::experimental;
queue Queue{default_selector{}};
float *PtrA = sycl::malloc_device<float>(N, Queue);
float *PtrB = sycl::malloc_device<float>(N, Queue);
float *PtrC = sycl::malloc_device<float>(N, Queue);
// Init device data
sycl_ext::command_graph Graph(Queue.get_context(), Queue.get_device());
Graph.begin_recording(Queue);
auto InitEvent = Queue.submit([&](handler& CGH) {
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrA[id] = 1.0f;
PtrB[id] = 2.0f;
PtrC[id] = 3.0f;
});
});
auto EventA = Queue.submit([&](handler& CGH) {
CGH.depends_on(InitEvent);
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrA[id] += 1.0f;
});
});
auto EventB = Queue.submit([&](handler& CGH) {
CGH.depends_on(InitEvent);
CGH.parallel_for(range<1>(N),[=](item<1> id) {
PtrB[id] += 1.5f;
});
});
auto EventC = Queue.submit([&](handler& CGH) {
CGH.depends_on(EventA);
CGH.depends_on(EventB);
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrC[id] += (PtrA[id] + PtrB[id]);
});
});
Graph.end_recording(Queue);
auto ExecGraph = Graph.finalize();
Queue.ext_oneapi_graph(ExecGraph);
Queue.wait_and_throw();
// Do something with the data
Explicit Graph Creation API
The explicit graph creation API provides more control over the definition of nodes and edges of the graph, and does not require a SYCL queue to record commands. However it requires more modifications to our base example code to use it.
Instead of submitting commands to the queue, we instead called add() on the modifiable graph. Calling add() will return an instance of the node class which is used for defining dependencies between nodes. When calling add() we simply pass the same command group function that the queue submissions used, and then optionally pass the property node::depends_on with any number of nodes to define dependencies, for example:
auto NodeA = Graph.add(
[&](handler& CGH) {
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrA[id] += 1.0f;
});
},
{sycl_ext::property::node::depends_on(NodeInit)});
Note that if we previously had calls to handler::depends_on to define dependencies as in the example, we must remove those since events are not returned from graph::add(). They can be replaced either with the property above or by calling graph.make_edge(srcNode, destNode) to explicitly define the dependency, for example:
Graph.make_edge(NodeInit, NodeA);
The final modified example code after these changes looks as follows:
using namespace sycl;
using namespace sycl_ext = sycl::ext::oneapi::experimental;
queue Queue{default_selector{}};
float *PtrA = sycl::malloc_device<float>(N, Queue);
float *PtrB = sycl::malloc_device<float>(N, Queue);
float *PtrC = sycl::malloc_device<float>(N, Queue);
// Init device data
sycl_ext::command_graph Graph(Queue.get_context(), Queue.get_device());
auto InitNode = Graph.add(
[&](handler& CGH) {
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrA[id] = 1.0f;
PtrB[id] = 2.0f;
PtrC[id] = 3.0f;
});
});
auto NodeA = Graph.add(
[&](handler& CGH) {
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrA[id] += 1.0f;
});
},
{sycl_ext::property::node::depends_on(InitNode)});
auto NodeB = Graph.add(
[&](handler& CGH) {
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrB[id] += 1.5f;
});
},
{sycl_ext::property::node::depends_on(InitNode)});
auto NodeC = Graph.add(
[&](handler& CGH) {
CGH.parallel_for(range<1>(N), [=](item<1> id) {
PtrC[id] += (PtrA[id] + PtrB[id]);
});
},
{sycl_ext::property::node::depends_on(NodeA, NodeB)});
auto ExecGraph = Graph.finalize();
Queue.ext_oneapi_graph(ExecGraph);
Queue.wait_and_throw();
// Do something with the data
Implementation
The 2024.0 release of DPC++ includes an experimental implementation of the command-graph extension. As such not all DPC++ backends, SYCL features and extension features are available for use. The implementation is in active development to increase support for these aspects. The only backend that is supported in 2024.0 is the oneAPI Level Zero backend. It is also important to note that experimental extensions may be subject to API breaking changes at any time.
The example shown in this post is designed to give the basics of using command-graphs and converting existing code to use them. For more detailed information about the APIs and examples please see the full extension specification.
Performance improvements should not be expected from this release of the extension, but future releases will work to unlock the potential performance improvements of this extension. The execution time of the kernels in a command-graph will also affect any performance increases from reduced host launch latency. Since this latency is largely fixed the relative effects would be seen most with kernels with short execution times.
Supported SYCL features in 2024.0:
- Kernel submissions.
- Memory copy operations.
- USM and Buffer support.
Future Work
The extension specification outlines some features which are planned for future revisions. Some features are already fully fleshed out, and some are more conceptual and subject to change. Future versions of the specification will focus on refining and including these features to expand the capabilities of command-graphs.
Priorities for future work on the implementation include:
- Adding an update feature to modify the graph input/output arguments between submissions.
- Increasing coverage of support SYCL features/node types.
- Support for CUDA backend to DPC++.
As mentioned previously the nature of a command-graph unlocks the potential for whole graph optimizations, including kernel fusion. There is work underway on a layered extension which would enable the use of the existing kernel fusion extension with command-graphs, which can be viewed here on Github.
Links to Further Information
- View the full specification on Github
- Talk: IWOCL & SYCLCON 2023 - Towards Deferred Execution of a SYCL Command Graph
- Graph Fusion extension proposal on Github
